Wikimedia API integration for Article Finder
31 May 2018Wikimedia is a huge organisation having an even bigger database, working with this large amount of data was a challenge in itself and posed several performance issues. During my first two weeks of coding period, I worked creating a V2 prototype for the article finder fully implemented on the client side. The earlier protoype which was completely implemented on the ruby backend faced several performance issue and was just a proof of concept to analyse the use cases of the tool. There were several reasons to shift the tool to client side but main reason was there was no need to save the data about the search results in the database which was what used to happen in the first prototype. We will just end up saving the huge database of Wikimedia affecting the response time.
To produce the filtered search result, we depend on the following APIs:
Working with APIs
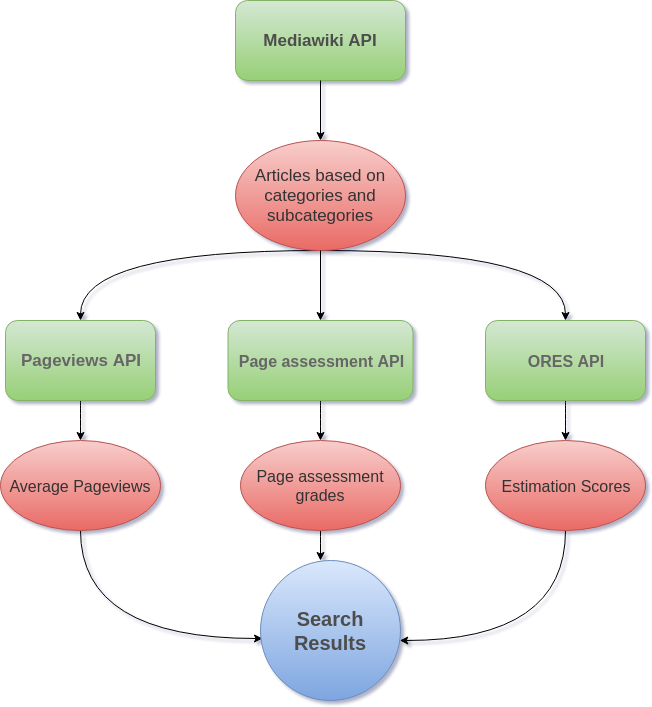 Data flow for the Article Finder
Data flow for the Article Finder
As it can be seen from the flowchart above, the search results are aggregated from the above 4 APIs. Initially a request is made to Mediawiki API to fetch the articles for a particular category, then several requests for the received articles are made to collect their assessment grades, pageviews and estimation scores. Integrating these APIs mainly involved working with Javascript Promises and Redux.
What are promises?
Promises are things which are not meant to be fulfilled! JK, Javascript promises can be defined as:
Javascript Promise object represents the eventual completion (or failure) of an asynchronous operation, and its resulting value.
Okay, I know that was cryptic. Let’s take up some keywords from that understand what promises are actually are.
Javascript is full of asynchronous actions, such as an AJAX request to a API endpoint. Callbacks were introduced to handle these async actions. The Callbacks pattern is awesome but also a nuisance to read and debug. This loss of readability is often referred as Callback Hell. Promises were introduced to handle this issue.
A promise is a object which is promised to give you a value at some point in time. A promise exists in one the following three states:
- Pending : The promise(or async action) is pending
- Success : The promise(or async action) is completed successfully
- Rejected : The promise(or async action) failed, due to some error.
The value of the promise can be accessed through the .then method passing a arrow function whose parameter is the value that the promise holds.
var promise = fetch("some/url/endpoint");
promise
.then((response) => {
console.log(response);
})
.catch((err) => {
console.log("Sorry! The promise failed");
})
Promise Chaining
The main advantage of using promises is promise chaining, executing async operations one after the other. The trick lies in the .then method, it also returns a promise, different from the original on which you can again use .then and .catch methods. It replaces the Callback Pyramid of doom with a beautiful and simplistic promise chain.
var promise = fetch("some/url/endpoint");
promise
.then((response) => response.json)
.then((response) => {
console.log(response);
})
.catch((response) => {
console.log("Sorry! The promise failed");
});
In the example above, we can again use the .then method, creating a chain of async actions executing one after another where each .then method receives the result of the previous. Pretty elegant, right?
Now, what will happen if the result of a .then method is also a promise?
In this case there is a exception. If the returned value is also a promise, then the further execution is suspended until it settles. After that, the result of that promise is given to the next .then handler.
var promise = fetch("some/url/endpoint");
promise
.then((response) => {
console.log("Response of 1st req: ", response);
return fetch("some/another/url/endpoint");
})
.then((response) => {
console.log("Response of 2nd req: ", response);
})
Here, the response of the 2nd request will only be printed only when fetch request for the 2nd URL is complete.
There is still much to left to talk about promises but let’s leave it for later. Some reference links for those who want to learn more about Promises:
Back to the Article Finder!
Well that was a lot of information! Going back to my project, it evident that the article finder will have a lot of requests going out to the APIs mentioned, each creating a promise. The promises are resolved and the redux state updated based on the collected data.
With the initial request to the Mediawiki API, we recieve a list of articles that come under the searched category. Similar request pattern and dataflow cycle take place for subcategories based on the depth making recursive calls. The state is updated with the received articles.
Next, we fetch the assessments for the articles via Pageassessment API. We filter the results based on the minimum grade used in the filter and make subsequent requests for ORES score only for those articles which match the filter.
After pageassessments are recieved and state updated, ORES scores are collected for the articles. Similar to pageassessment, we filter the results based on the Max Completeness searched for.
Lastly, we make requests to the Pageviews API to recieve the average views for the articles and filter the results.
Limiting concurrency
With all these requests occuring simultaneously, we had to limit the concurreny of the requests. In case of promises, as soon as a promise object is created, the request is made to the API leading to alot of concurrent requests which could easily crash the client if searched for a large category or hit the maximum number of request to the external service in a time period.
To limit the concurrency, we opted to go with Promise Limit. Promise Limit is a easy to use npm module which limits the concurrency based on your requirements. Checkout its Github repo for more details.
Issues faced!
The huge number of requests being made introduces a lot performance issues. With the increasing depth search, the number of resulting articles and in turn the number of requests grow rapidly. Currently, for a large category such as Feminism, with depth set to 1, we experince sluggish page behaviour which often leads to page crash. A depth search for two levels is not feasible for most of the categories. To tackel these issues with increasing depth, we are thinking of limiting the search results as of now. There are several ways to go which will require appropriated changes in UI too.
What’s next?
Next, I will be working on integrating the current prototype with the dashboard, adding hooks to add articles from the results to the list of available articles for a course. I will be having a parallel discussion regarding the UI and increasing depth issue with the mentors.
Thanks for reading! Stay tuned for more updates!